
 研报速递
研报速递这不是年终数据,是今年前五个月的数据。

每日一罚
1.33亿是什么概念?
平均每3天就有1家券商接到罚单,单笔最高4305万元。
天风证券年内11张罚单,违规向股东输送利益,年报多项重大遗漏,公司及责任人合计罚款超3000万,暂停代销私募基金业务两年。
中天国富在东旭光电非公开发行中财务顾问文件虚假记载,被罚没超4305万元,暂停财务顾问业务许可六个月。
国都证券短期连收6张罚单,项目负责人被认定为不适当人选。
头部机构也未能幸免——中信建投、国泰君安、海通证券分别因保荐项目违规被出具警示函。
更值得关注的是违规重心的迁移:从投行蔓延到经纪业务。2026年,经纪业务相关处罚已达63条,跃升为第一大"雷区"。从总部到营业部,从高管到一线员工,"穿透式监管、全链条问责"正在全面落地。
处罚密度在加速,范围在扩大。
中证协破局思路
其实,监管自己也在找解药。
2026年5月,中国证券业协会启动证券公司合规管理有效性评估专项调研,首次明确提出 "探索AI、智能体等新兴技术在合规评估领域的应用"。
核心逻辑直白:人工审查跟不上每天152条的处罚节奏,用AI来帮监管做合规检查,提升效率、减少遗漏。
这听起来像是一个合理的技术方案。但问题随之而来——
谁来审计AI?
合规判断本身涉及信息披露完整性、内控质量、勤勉尽责等高度依赖具体情境的判断,大模型在此类任务中的幻觉率高达12.2%(2025年斯坦福CRFM研究数据)。当AI代替人工做出合规结论时,如果它出错、遗漏、或被诱导生成有利但虚假的判定,追责链条指向谁?
技术开发者?使用机构?还是AI本身?
所以呢:AI合规的前提,是AI本身可被审计。
核心悖论
中证协推AI合规,隐含一个需要成立的前提:AI的合规判断是可信的。
但这个前提,恰恰没有被验证过。
大语言模型在企业合规判断上的可靠性,目前只有少量学术研究(如2025年UC Berkeley等高校的"LegalBench"评测),未进入任何监管验证体系。
而且这些评测针对的是美国成文法环境下的法律推理,对A股信息披露、中国证监规则、交易所自律规则的适用性——几乎没有公开数据。
换句话说,中证协是在没有"AI合规能力验证标准"的情况下,直接推动AI进入合规评估。
这不是技术问题,是制度真空。
所以,推AI之前,先建AI的验证标准。
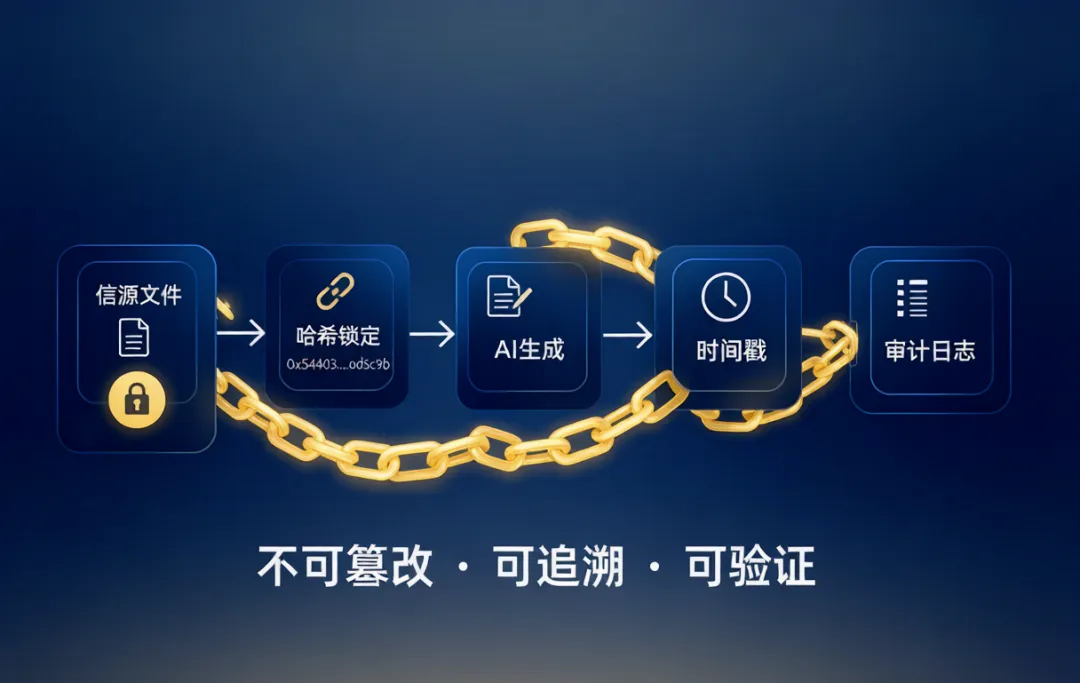
"谁来审计AI"这个问题,答案应该前置在产品设计里,而不是事后补救。
这就要用到SHA-256审计链。
不讲技术语言,SHA-256审计链就是每次AI生成内容,自动产出包含:内容哈希、信源清单、操作日志的审计包。
审计包不可篡改,不可事后替换。如果外部质疑"这条结论从哪来的",可以精确追溯——哪个信源、什么时间、什么置信度。
48家券商被罚的事件告诉从业者一件事:合规不是一次性的,是可追溯的。
当监管问"你怎么得出这个结论的",你不能说"AI说的"。
另外,结合链上数据的颗粒度算法;CRAAP 评分算法;Prompt 工程(合规护栏 + 语料风格注入的具体参数),让每篇内容都有“保障”。
所以,对AI来说,审计别人之前,先让自己可被审计。
下期预告 · 「证据链拆解」这张图里,哪些东西可以造假?欢迎关注。
参考文献:1. 2026年1-5月证监会/各地证监局行政处罚决定汇总2. Stanford CRFM, "Evaluating Large Language Models", 20253. UC Berkeley et al, "LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning", 2025
声明:本文所述案例来自公开处罚决定,观点仅代表作者。不构成投资建议,亦不代表所在机构立场。
关注「思想界」,不谈"AI写作革命"——只做一件事:让AI生成的金融内容,经得起监管检查。



发表评论
发表评论: