
 研报速递
研报速递导言:如果说AI算法工程师、AI产品经理是券商智能化转型中人人争抢的"显眼位",那么本文介绍的五个扩展岗位则处于另一种尴尬——通常没人写在战略规划里,但出了问题有时第一个被骂。它们是:让AI在金融语境中稳定输出的上下文工程师(❻)、教AI读懂金融的AI对话训练师(❼)、终结烟囱式建设的大模型架构管理岗(❽)、让知识库从"建完即荒废"到"持续活跃"的AI知识运营官(❾),以及把AI项目真正落地的AI知识工程师(❿)。
本文为系列扩展篇,衔接总篇(券商AI人才战)的岗位框架,深入展开五个容易被忽视但不可或缺的扩展岗位。
四维定位
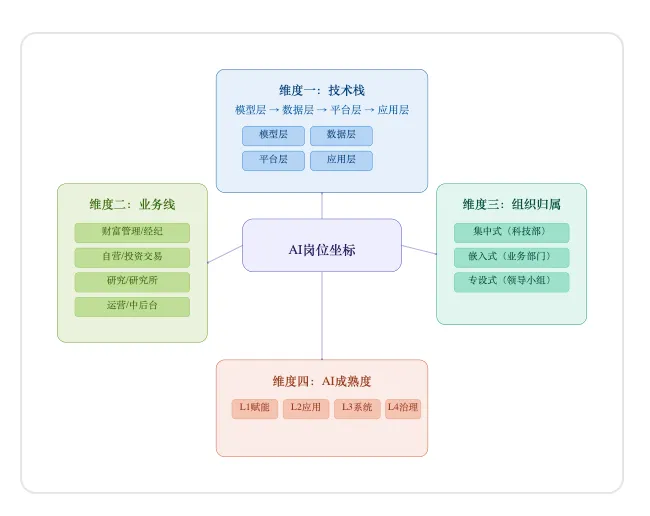
一、上下文工程师(❻)——让AI在金融语境中稳定输出
1.1 一个被严重低估的问题
大模型的表现高度依赖"上下文"——你给它什么背景信息,它就能基于什么信息回答。但金融场景的上下文工程,比通用场景复杂得多。
为什么?因为金融文本的特点:
数字密集:一个"净利润增长10%"在不同上下文中可能是好消息(低基数)或坏消息(高预期) 时间敏感:前一段时间的研报观点可能已经失效 监管措辞精确:合规文件中"应当"和"可以"意味着完全不同的合规要求 专业术语歧义:"平仓"在期货和融资融券里是不同含义
上下文工程师就是负责"把上下文搞对"的人——让AI在金融场景中稳定、准确地输出。
1.2 这个岗位在做什么
| Prompt工程(金融垂直) | ||
| 上下文窗口管理 | ||
| RAG输出优化 | ||
| 输出格式控制 |
与Prompt工程师的区别:Prompt工程师的岗位边界正在模糊——它的核心技能(写Prompt模板)实际上已经被纳入AI产品经理和AI应用开发工程师的职责。上下文工程师的不同在于:它聚焦金融垂直场景的上下文理解问题,这不是通用Prompt工程能解决的。
1.3 为什么这个岗位在券商特别重要
因为券商的AI应用对"准确性"的要求高于通用场景。
通用场景:AI回答错了一个冷笑话,影响较小 券商场景:AI把"卖出"建议写成"买入",客户可能亏损,公司可能被投诉
而"准确性"的上游,就是上下文质量。上下文错了,再好的模型也输出不了正确结果。
1.4 能力模型
| 金融文本深度理解 | ||
| Prompt工程实战 | ||
| RAG理解 | ||
| 细节偏执 |
1.5 成熟度建设路径
| L2起步 | ||
| L3专职 | ||
| L4深化 |
二、AI对话训练师(❼)——教AI读懂金融对话
2.1 当AI开始做客服
券商的AI客服、AI投资顾问助手、AI合规审查助手……这些对话式AI产品正在快速上线。
但一个根本问题:AI能理解客户在说什么吗?
金融对话的特殊性:
客户说"我的收益怎么亏了"——AI需要理解他指的是哪只产品、哪个时间段 客户说"能不能融"——AI需要理解他是在问融资融券业务 客户说"这个票今天怎么了"——"票"是A股股民的口语,指"股票"
AI对话训练师就是负责"教AI理解金融对话"的人——通过标注训练数据、设计对话流程、持续优化意图识别准确率。
2.2 这个岗位在做什么
| 意图识别优化 | ||
| 对话流程设计 | ||
| 金融口语标注 | ||
| 持续效果监控 |
与AI知识工程师的区别:AI知识工程师处理"静态知识"(研报、法规);AI对话训练师处理"动态对话"(客户说的话、AI的回复)。
2.3 为什么银行已设岗、券商还未设
银行客服的场景更成熟、对话数据更丰富,因此先行一步。公开信息显示,部分银行信用卡中心已设立"AI智能训练主管岗"。
券商正在追赶:随着智能客服、AI投资顾问助手的上线,对话训练的需求会快速显现。预计未来,头部券商会开始设立这个岗位。
2.4 能力模型
| 金融业务理解 | ||
| 对话数据敏感性 | ||
| 标注规范设计 | ||
| 用户视角 |
2.5 成熟度建设路径
| L2起步 | ||
| L3专职 | ||
| L4深化 |
三、大模型架构管理岗(❽)——终结"烟囱式"建设
3.1 券商AI建设的一个顽疾
很多券商的AI建设是"烟囱式"的:研究所自己搞一套大模型,合规部自己搞一套,财富管理又自己搞一套。结果就是:
重复采购算力(每个部门都买了一堆GPU,但利用率都很低) 模型版本混乱(研究所用的是某模型的版本A,合规部用的是版本B,效果不一致) 数据孤岛加剧(每个部门的数据不互通,大模型的能力被锁死在部门内)
大模型架构管理岗就是负责"终结烟囱"的人——从架构层面强制统一。
3.2 这个岗位在做什么
| 统一模型服务层设计 | ||
| 算力资源统一调度 | ||
| 数据治理架构 | ||
| 技术标准制定 |
与AI应用架构师的区别:AI应用架构师关注"单个AI应用怎么设计得好用";大模型架构管理岗关注"公司所有AI应用的模型层怎么统一管理"。
3.3 为什么这个岗位通常只有L3以上的券商才需要
L1/L2的券商,AI应用数量较少,"烟囱"的规模还不够大,统一架构的收益不明显。
L3的券商,AI应用数量达到一定规模,"烟囱"开始造成明显的资源浪费和效果不一致,此时设立这个岗ROI最高。
3.4 能力模型
| 大模型技术理解 | ||
| 算力架构设计 | ||
| 跨部门影响力 | ||
| 数据安全意识 |
3.5 成熟度建设路径
| L2起步 | ||
| L3强制 | ||
| L4优化 |
四、AI知识运营官(❾)——让知识库从"建了"到"用了"
4.1 一个反常识的事实
很多券商花了大价钱建"AI知识库",建完之后……没人用。
原因不是AI不够聪明,而是没有人负责"让知识库被用起来"。这听起来像废话,但这就是AI知识运营官存在的全部理由。
AI知识运营官的核心工作:不是写代码,而是运营"知识"这个产品——让对的人、在对的场景、用上对的AI知识能力。
4.2 这个岗位在做什么
| 知识采集协调 | ||
| 知识质量管控 | ||
| 用户推广与培训 | ||
| 使用数据分析 |
与AI知识工程师的区别:AI知识工程师负责"让AI能检索到知识"(技术管道);AI知识运营官负责"让业务人员愿意用这个AI知识工具"(运营推广)。
4.3 为什么这个岗位容易被忽视
因为它看起来"不像技术岗"。在券商的IT部门,写代码的岗位更容易被写进headcount。但事实是:一个AI知识库项目失败,相当部分原因在"没人运营",只有少部分在"技术不够好"。
中小券商尤其容易忽视这个岗位——"我们先把系统建起来,用的人会有的"。结果就是:建完即荒废。
4.4 能力模型
| 业务理解 | ||
| 跨部门协调 | ||
| 数据分析 | ||
| 产品思维 |
不是必须的(但加分):
有研究所/合规部/风控部业务经验(知道用户痛点) 社区运营或内容运营经验(知识运营本质上是内容运营)
4.5 成熟度建设路径
| L2起步 | ||
| L3扩展 | ||
| L4治理 |
五、AI知识工程师(❿)——RAG"最后一公里"的修路人
5.1 这个岗位在做什么
一个典型场景:某券商花三个月上线了研报智能问答,用户反馈问答准确率不理想——要么找不到相关研报,要么引用了多年前的过期数据,要么把不同行业的观点张冠李戴。技术团队说"模型没问题,是数据的问题"。
AI知识工程师就是负责让"数据没问题"的人。
核心职责:
| 知识结构化 | ||
| RAG管道搭建 | ||
| 知识图谱构建 | ||
| 效果持续调优 |
与数据工程师的区别:数据工程师处理结构化数据(ETL、数仓、BI报表);AI知识工程师处理非结构化知识的"可检索性"——不是把数据存进去,而是让AI能准确把它找出来。
5.2 为什么RAG效果普遍不及格
业界普遍认为,大量企业RAG项目效果不达预期。根因在知识管道,不在模型。
根因1:分块策略不考虑金融文本特殊性
通用"每500 token切一刀"的方法,对研报是灾难。一篇研报的逻辑链是:宏观判断→行业景气度→公司竞争优势→业绩预测→投资建议,环环相扣。切断之后,AI要么只看到结论看不到依据,要么只看到依据看不到结论。
金融文本分块需要考虑:章节层级结构、表格完整性、数字与单位的配对、时间标注的保留。
根因2:embedding模型对金融术语理解偏差
通用embedding模型(如text-embedding-ada-002)对"浮盈"和"浮亏"的向量距离可能很近,但在投资场景里它们代表完全相反的含义。金融垂直术语需要垂直微调过的embedding模型。
根因3:知识更新机制缺失
研报的时效性极强。假设某年某券商研报给出"买入"评级,到近年该券商可能已被下调至"中性"。如果知识库没有基于时间的加权或过期淘汰机制,AI会用过期知识回答问题——这在合规上是严重问题。
根因4:评估体系缺失
大多数券商的RAG项目上线后,没有"检索准确率""知识覆盖率""bad case率"等度量指标。没有度量就没有优化方向。
5.3 能力模型
| NLP基础 | ||
| RAG框架熟练度 | ||
| 金融文本理解 | ||
| 向量数据库操作 | ||
| 评估思维 |
不是必须的(但加分):
图数据库(Neo4j)经验(知识图谱需要) 大模型微调经验(当通用embedding不够用时,需要微调)
5.4 成熟度建设路径
| L2起步 | ||
| L3扩展 | ||
| L4治理 |
小结:五个扩展岗位的共同逻辑
核心判断:这五个岗位不像"AI算法工程师"那样光鲜亮丽,它们是支撑性岗位——没有它们,前台的AI应用很难真正落地。但对于L1/L2的券商,优先级是:先有前台应用,再补支撑岗位。
免责声明:本文所引用信息均来自公开渠道,仅供行业分析参考,不构成任何招聘建议或投资建议。文中涉及的各券商岗位信息以各公司官方发布为准,实际情况可能因券商具体情况而异。





发表评论
发表评论: