
 研报速递
研报速递
一、一个273万亿市场的"翻译"难题
中国债券二级市场2024年成交额突破273.54万亿元,体量是股票市场的十倍。但这个庞大市场的运转方式却出人意料地"原始"——绝大多数交易不是在标准化的交易所完成,而是通过场外交易(OTC):交易员们在微信群、私聊窗口里扔出各种报价消息,broker得像淘金一样从这些聊天碎片里筛出有效信息,撮合买卖双方。
一条典型的RFQ(Request-for-Quote,报价请求)消息长这样:
"CCB Trust bid 102382759 next day+0, flat to valuation"
或者更复杂的:
"3.8/3.60*~/3000" —— 表示bid价3.8、offer价3.60,带星号需审批,面值3000万元
broker的核心竞争力是快。一条好报价晚匹配几秒,可能就被同行截胡。在平均单笔交易600万元的量级下,这种延迟直接折算成财务损失。问题是,这些消息全是自由文本,没有统一格式,broker过去只能靠人工逐条阅读、理解、录入系统——我们称这个过程为RFQ解析。
论文把这一任务定义为:从非结构化聊天文本中,提取包含18个字段的结构化交易记录(债券代码、买卖方向、价格、面值、结算速度、评级等)。
二、三个让通用AI"翻车"的硬骨头
硬骨头一:金融黑话的"语义迷宫"
债券交易有自己的方言体系。"valuation+1"在训练数据里几乎总是表示"按估值价加1元成交",但市场演化后出现了"+1 3.31 1.85Y"这种写法——这里的"+1"其实是T+1结算的意思,3.31才是价格。同一个符号,位置不同、搭配不同,意思截然不同。通用大模型没见过这种"黑话变体",很容易按老经验误读。
硬骨头二:长消息里的"俄罗斯套娃"
普通信息抽取任务假设"一条消息一个记录",但真实RFQ完全不是这样。平均一条消息塞了11.13条独立报价记录,多的能有几十条。这些记录还玩"共享上下文"——开头几行是公共信息,后面每条记录各自补充细节。整段扔给模型解析,不仅慢,还容易把A记录的价格套到B记录头上。
硬骨头三:市场在变,模型不能"失忆"
新债券品种、新交易习惯、新入行broker的表达方式……RFQ的格式永远在演化。传统正则表达式方案F1只有67.2%,且维护成本随规则膨胀而指数增长;直接拿通用LLM(如gpt-4o)来用,F1能到85%,但遇到新pattern照样抓瞎,重训模型又贵又慢。
三、Chat2Trade的三板斧:分块、检索、生成
针对上述问题,论文提出了一套"先拆后学再组装"的流水线,三个模块环环相扣:
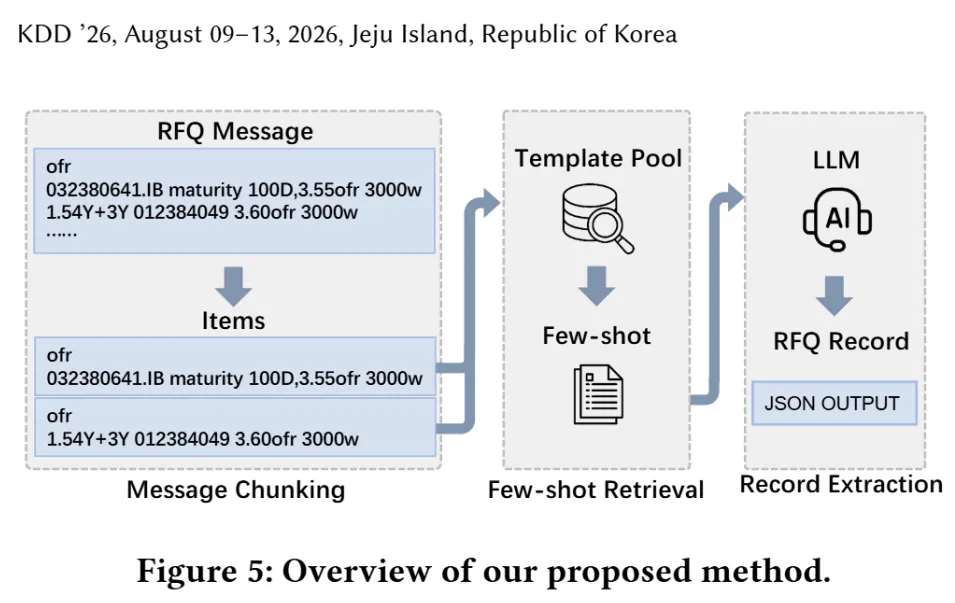
第一板斧:消息分块——把"套娃"拆成独立零件
算法逐行扫描RFQ消息,识别两种关键行:
独立行:包含债券名称或代码,意味着"这里开始一条新记录" 共享行:不含债券标识,但携带了后续记录共用的上下文(比如统一的结算方式或评级前缀)
每条独立行往前"拉"上它前面的共享行,拼成一个完整的RFQ条目。原本最长4829 token的输入被压缩到922 token,输出从25088 token砍到1561 token。更关键的是,拆完后各条目可以并行处理,推理速度大幅提升。
第二板斧:少样本检索——让历史案例"现场教学"
债券报价的格式有强烈规律性。"ofr [代码] [价格]"和"bid [代码] [价格]"的解析逻辑几乎一样,模型不需要从零学,只需要"看几个例子就懂"。
系统先把历史训练数据模板化:把具体的数字、代码替换成占位符,保留结构骨架,建成模板库。遇到新消息时,同样做模板转换,用最长公共子序列(LCS)相似度快速找到最像的历史案例:
再用最大边际相关性(MMR)重排序,确保选出来的例子既相关又多样,避免"三个例子其实一回事"的冗余:
最后设个相似度门槛,太不像的干脆不放进提示词,防止模型被带偏。
第三板斧:记录抽取——在提示词里"开卷考试"
把分好的条目和检索到的少样本示例一起塞进微调后的LLM,让它照着例子"临摹"输出JSON。由于分块偶尔会把一行拆错或漏拆,最后再加一道去重校验,删掉重复或重叠的记录。
四、工程里的魔鬼细节
训练配方
基于Qwen2.5-1.5B和3B两个版本微调,batch size压到2,学习率,上下文窗口5120 token。为防止长消息里相似条目过多导致模型"偏科",每条长消息最多采样5个代表性条目训练。
损失函数是标准的自回归交叉熵:
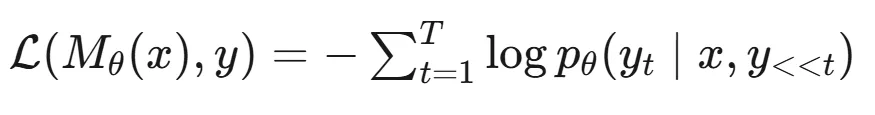
CUDA内核加速:让检索飞起来
LCS相似度计算是整套系统的速度瓶颈。10,000条模板用CPU算要近1秒,完全无法满足实时交易需求。团队手写CUDA内核,256线程并行,x轴分发检索任务、y轴并行LCS计算,共享内存存模板、寄存器存临时变量——最终0.04秒搞定,提速25倍。
投机解码:猜对了就跳过
用一个小草稿模型预生成token,大模型批量验证。因为RFQ输出是高度模板化的JSON,小模型猜中的概率很高,猜对了大模型直接跳过,猜错了再老老实实逐token生成。这招让吞吐量从基线提升到19.4 requests/s,增幅50%。
五、数字说话:精度与速度的双重跨越
解析精度对比(Table 2)
| Chat2Trade-1.5B(本文) | 95.42 | 95.04 | 95.23 | |||
| Chat2Trade-3B(本文) | 95.16 |
几个值得品味的结论:
1.5B微调 > 通用大模型:Chat2Trade-1.5B的F1比gpt-4o高出10个百分点,说明在垂直领域,"对症下药"比"大力出奇迹"更有效 小模型+好架构 > 大模型+零样本:1.5B版本在速度和精度上双杀3B版本,工程优化释放了硬件潜力 规则系统快但不可用:RegExp吞吐虽高,但每三条记录就错一条,生产环境无法容忍
持续学习:新黑话来了怎么办?
金融市场永远在变,模型部署后必然遇到训练时没见过的表达。论文设计了四阶段持续学习实验:基线 → 加入OOD1数据 → 加入OOD2 → 加入OOD3。
Chat2Trade的少样本适配策略(只更新模板库,不碰模型参数)在三阶段分别带来**+18.36%、+9.01%、+17.25%**的累积提升。作为对比,参数高效的DoRA方法仅提升4%-5%,且越学越忘;全量重训虽然能追上,但每阶段都要重新训练模型,成本不可接受。
消融实验:每个模块值多少?
抽掉检索:F1掉1.9分(95.23→93.33),少样本示例是精度的重要保险 抽掉分块:F1掉5.5分(95.23→89.70),直接退化成朴素微调,长消息处理能力崩塌 把模板检索换成向量检索(bge-m3):F1掉15.5分(95.23→79.69),证明结构相似性比语义相似性对RFQ任务更关键 抽掉长消息下采样:F1掉2分,且长消息过拟合导致泛化变差
六、从论文到交易大厅:10个月的真实部署
Chat2Trade已在China Securities Co., Ltd.(中信建投证券)生产环境运行超10个月,支持100余名broker,高峰期每小时处理2,035条RFQ。
论文设计了一个扎实的A/B测试:部署前,使用系统的broker组(A组)日均交易量仅为对照组(B组)的0.73倍;部署后,A组跃升至B组的2.67倍——相对交易量增长了3.67倍。broker的工作流从"主动翻聊天记录找机会"变成"系统实时推送匹配报价",交易机会捕获效率发生质变。
七、留给行业的思考
Chat2Trade的价值不止于一个债券交易工具,它示范了垂直领域LLM应用的几个关键原则:
领域知识要"显式"注入:与其指望模型自己悟出"valuation+1"和"+1 3.31"的区别,不如通过模板检索把相关案例送到它眼前 结构感知优于语义感知:对高度格式化的金融文本,LCS这种"看骨架"的相似度,比embedding这种"看意思"的相似度更靠谱 轻量持续学习是落地关键:金融数据分布永远在漂移,重训模型不现实,少样本检索提供了一条"不修改模型就能适应新pattern"的务实路径 小模型+系统工程 = 大模型效果:在特定任务上,1.5B模型配合精心设计的分块、检索、解码优化,完全可以超越通用大模型的零样本表现

(加入星球,获取论文和其它资料)




发表评论
发表评论: