
 研报速递
研报速递 



刚刚读到一篇超震撼的技术报告!Ling 2.0团队发布了他们的万亿参数推理导向语言基础模型,这简直是AI领域的一次重大突破!🚀
研究背景与动机:
随着大模型参数规模不断增长,如何平衡计算效率和推理能力成为关键挑战。传统密集模型在万亿参数级别面临巨大的训练和推理成本,而Ling 2.0通过创新的高稀疏混合专家架构,成功将模型扩展到1万亿参数规模!
研究方法:
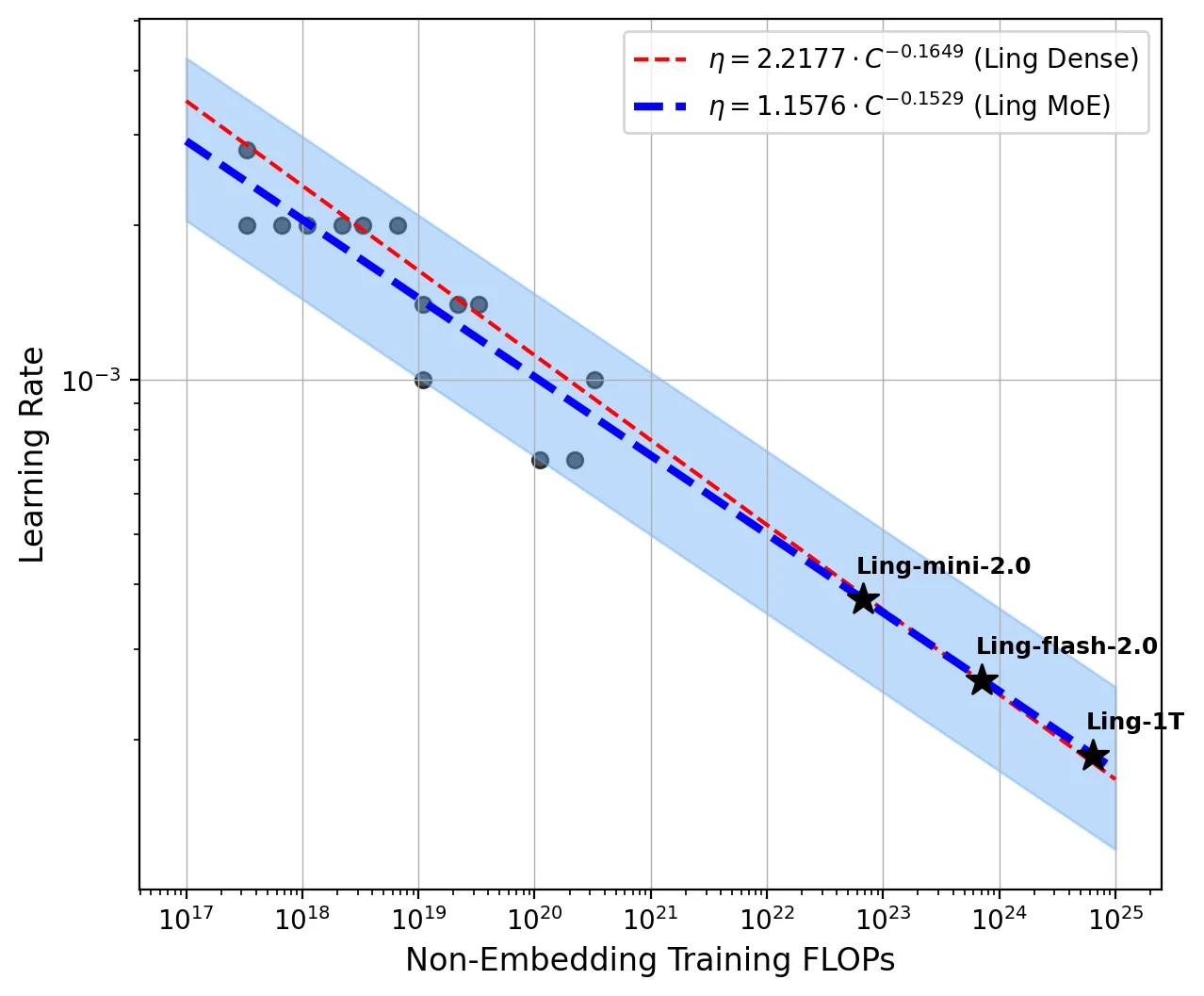
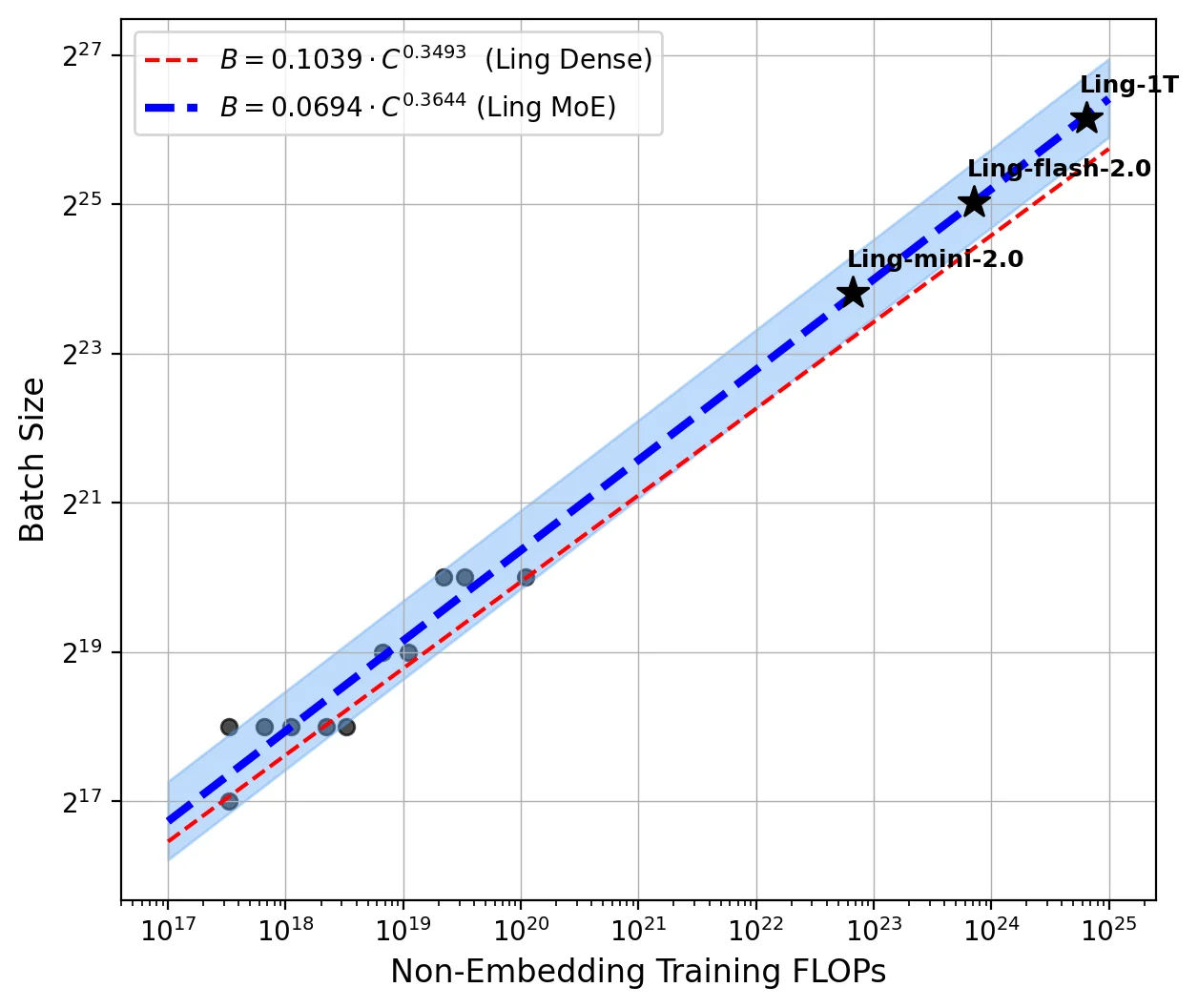
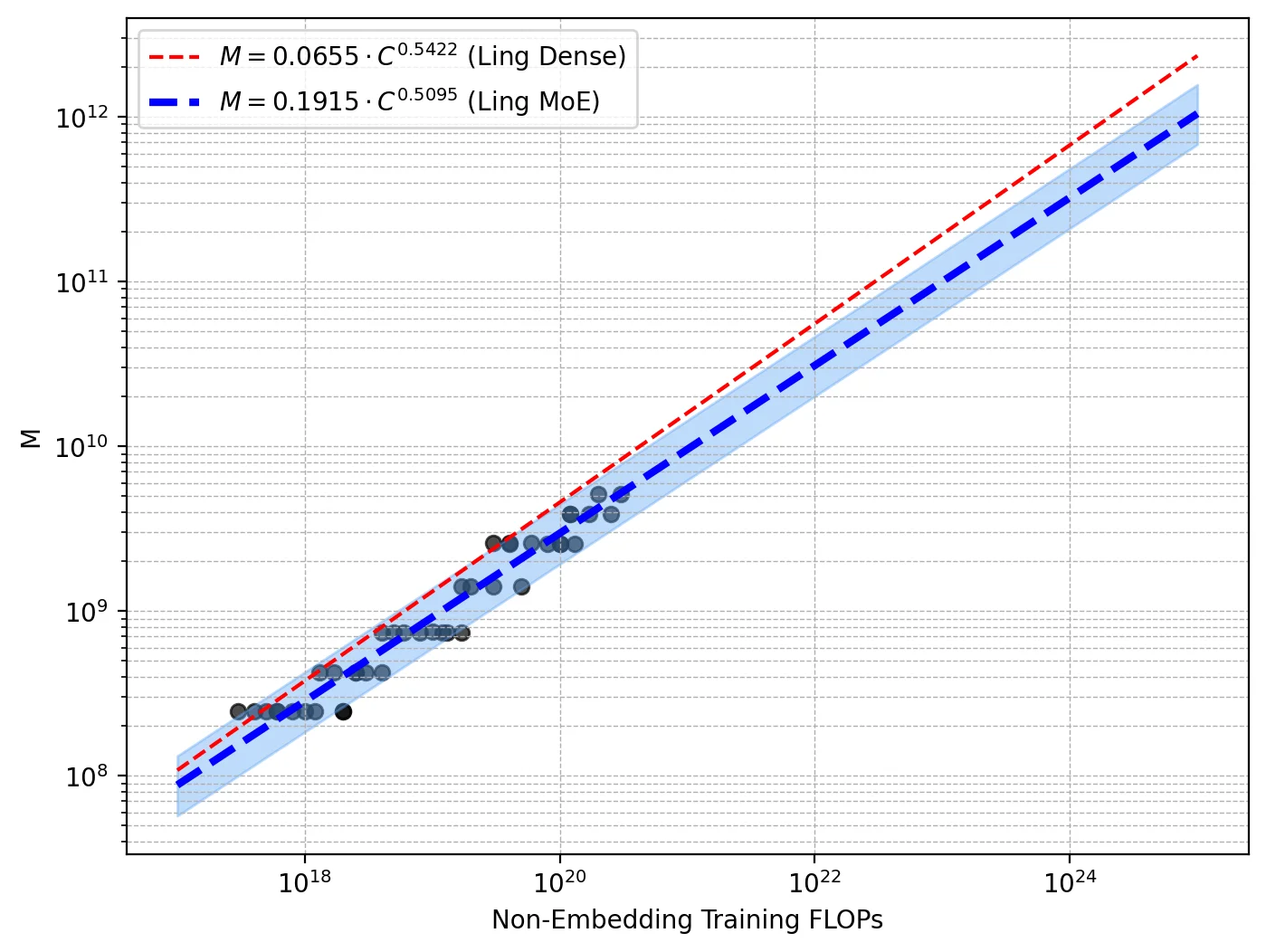
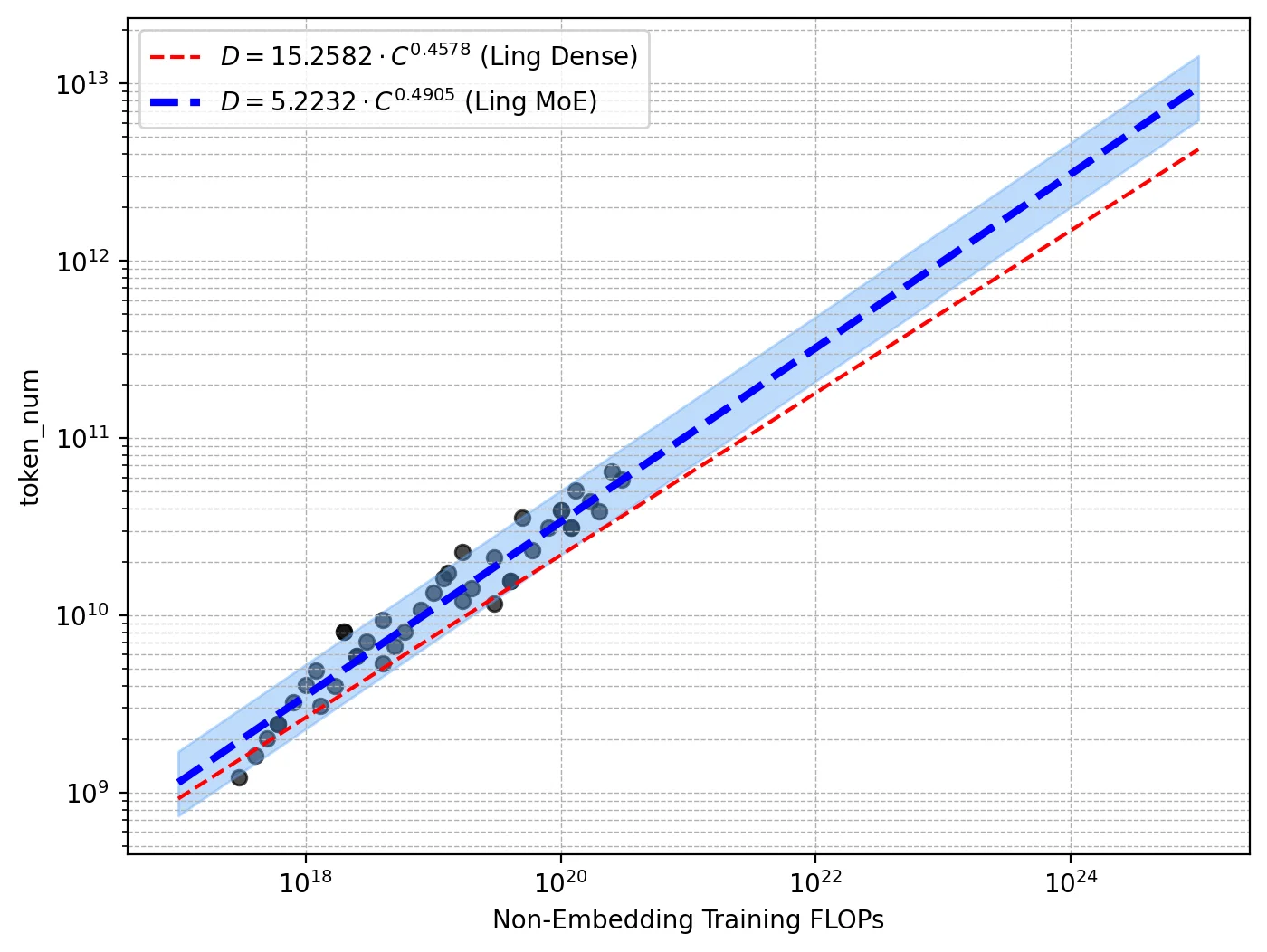
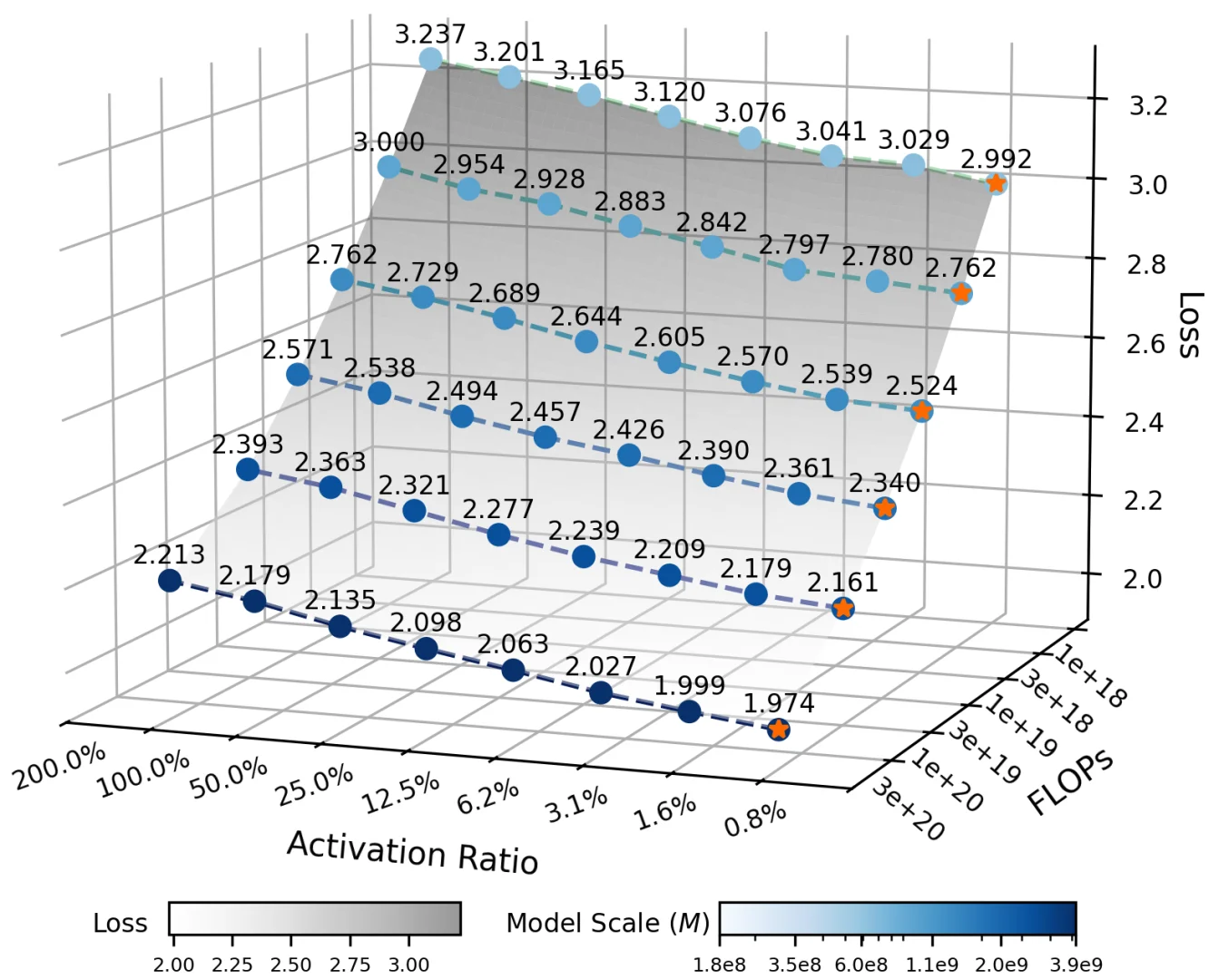
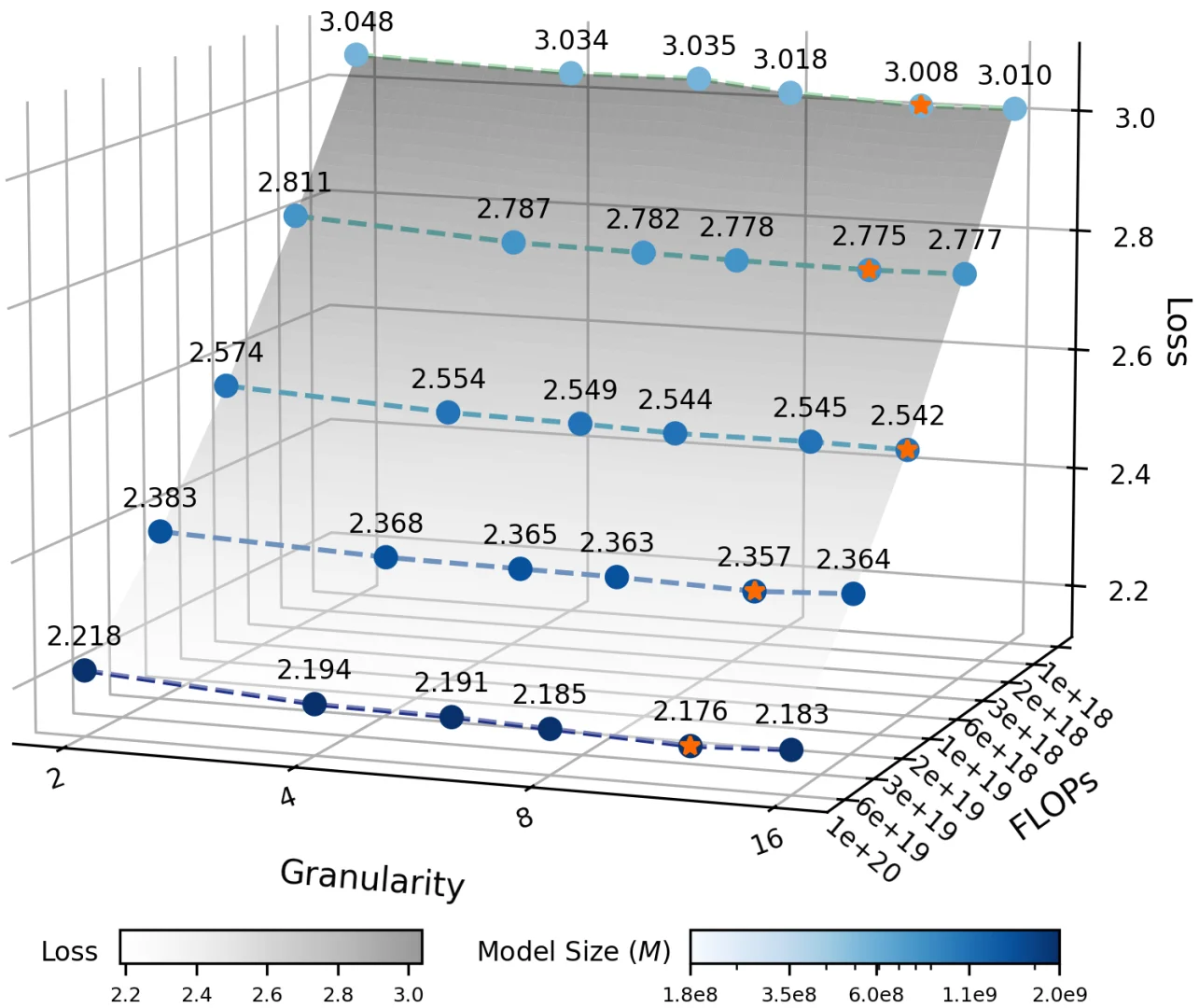
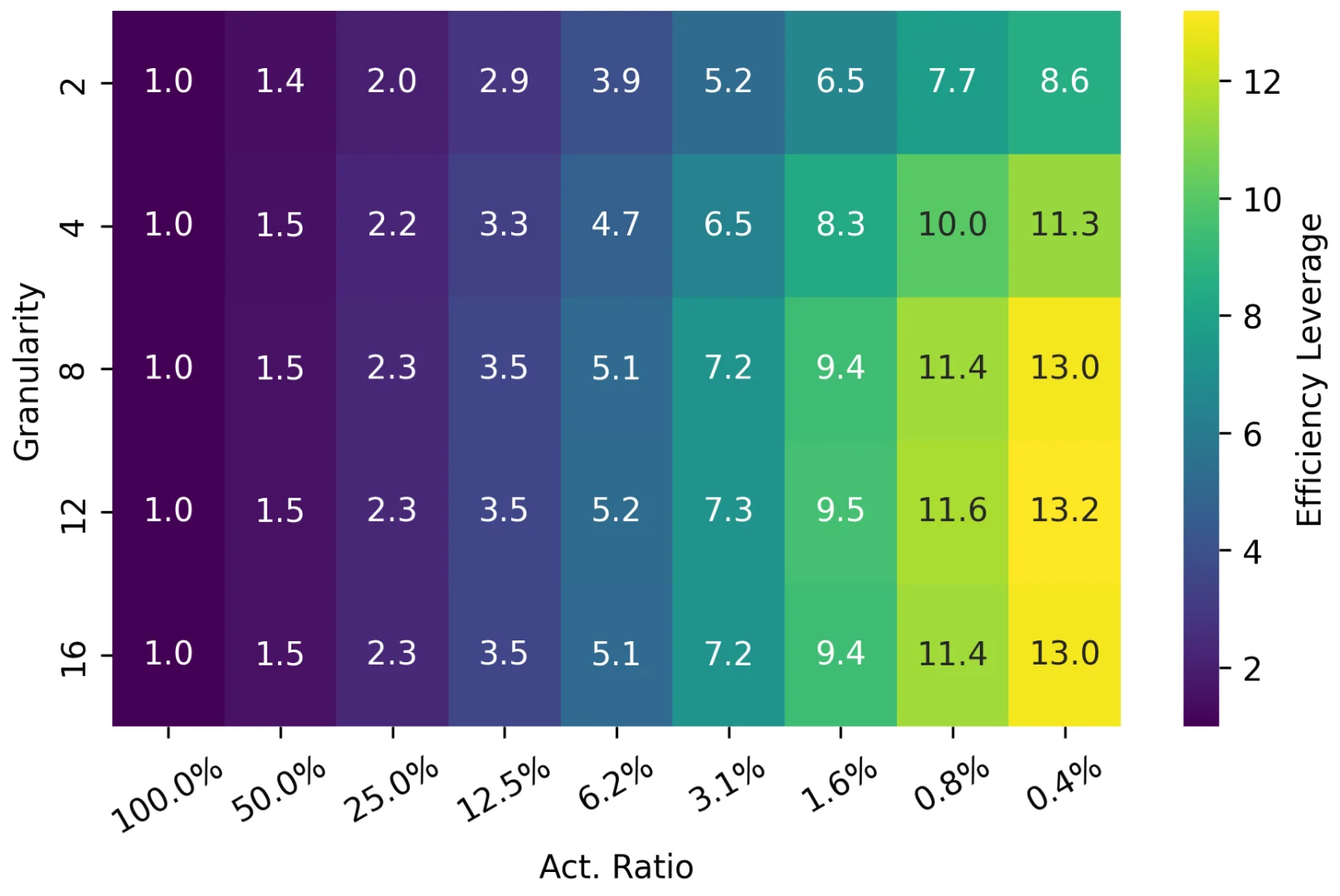
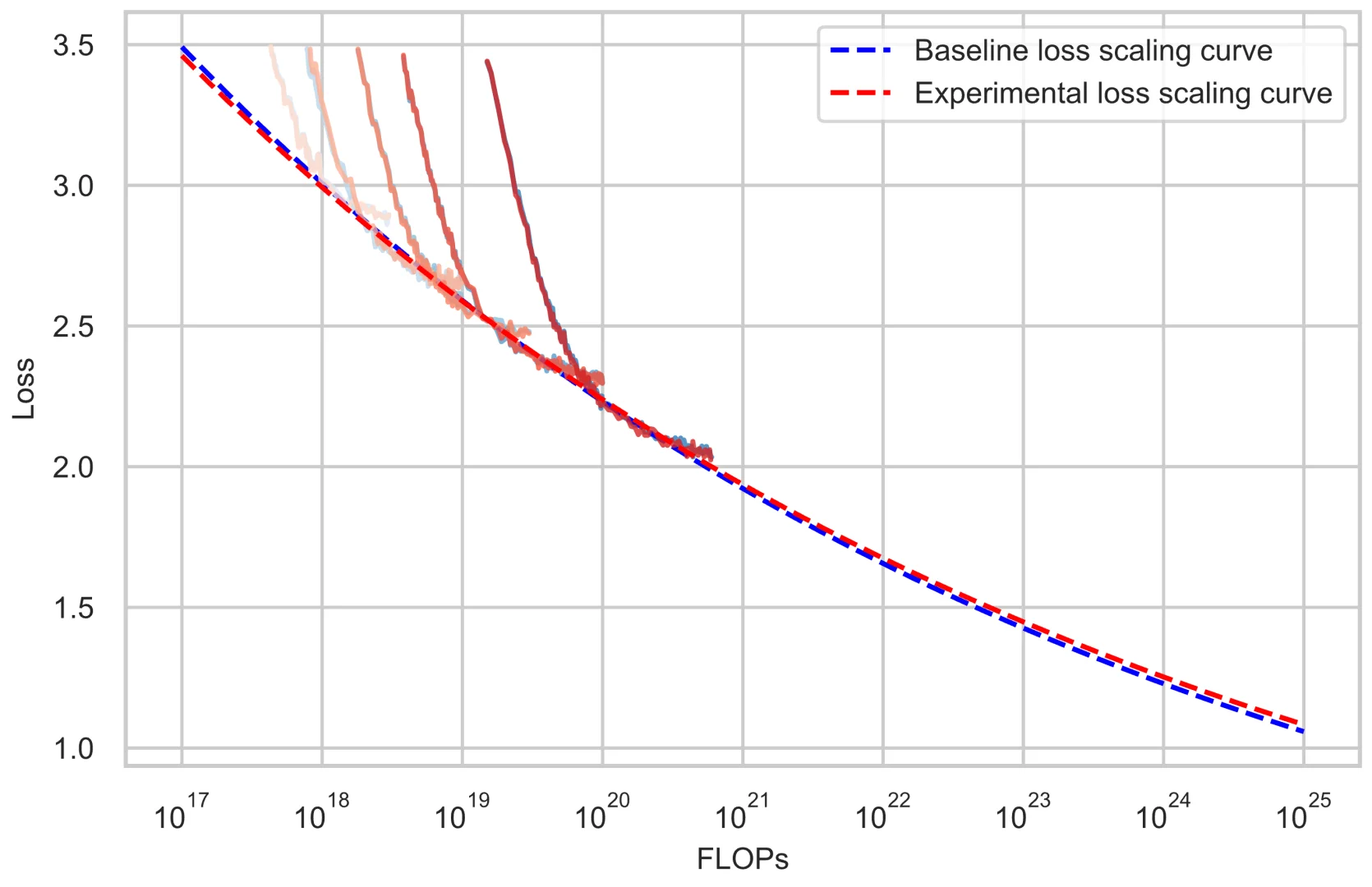
Ling 2.0采用了256个路由专家+1个共享专家的高稀疏设计,每个token只激活8个专家,整体激活率仅3.5%!这种设计大幅降低了计算成本,同时保持了强大的推理能力。他们还开发了Ling Scaling Laws、推理导向数据组合、DFT初始化与Evo-CoT等创新技术。
实验验证:
团队构建了三个模型变体:Ling-mini-2.0(16B)、Ling-flash-2.0(103B)和Ling-1T(1T参数)。通过Ling风洞实验系统验证了架构效率,在多个基准测试中表现出色!
关键结论:
高稀疏MoE架构是实现万亿参数模型的有效路径,Ling 2.0在保持强大推理能力的同时,显著降低了计算成本。这为未来更大规模的语言模型发展指明了方向!
未来工作:
团队将继续优化模型架构,探索更高效的训练方法,并扩展模型的应用场景。万亿参数时代真的来了!
论文链接:https://arxiv.org/pdf/2510.22115
研究背景与动机:
随着大模型参数规模不断增长,如何平衡计算效率和推理能力成为关键挑战。传统密集模型在万亿参数级别面临巨大的训练和推理成本,而Ling 2.0通过创新的高稀疏混合专家架构,成功将模型扩展到1万亿参数规模!
研究方法:
Ling 2.0采用了256个路由专家+1个共享专家的高稀疏设计,每个token只激活8个专家,整体激活率仅3.5%!这种设计大幅降低了计算成本,同时保持了强大的推理能力。他们还开发了Ling Scaling Laws、推理导向数据组合、DFT初始化与Evo-CoT等创新技术。
实验验证:
团队构建了三个模型变体:Ling-mini-2.0(16B)、Ling-flash-2.0(103B)和Ling-1T(1T参数)。通过Ling风洞实验系统验证了架构效率,在多个基准测试中表现出色!
关键结论:
高稀疏MoE架构是实现万亿参数模型的有效路径,Ling 2.0在保持强大推理能力的同时,显著降低了计算成本。这为未来更大规模的语言模型发展指明了方向!
未来工作:
团队将继续优化模型架构,探索更高效的训练方法,并扩展模型的应用场景。万亿参数时代真的来了!
论文链接:https://arxiv.org/pdf/2510.22115






发表评论
发表评论: