
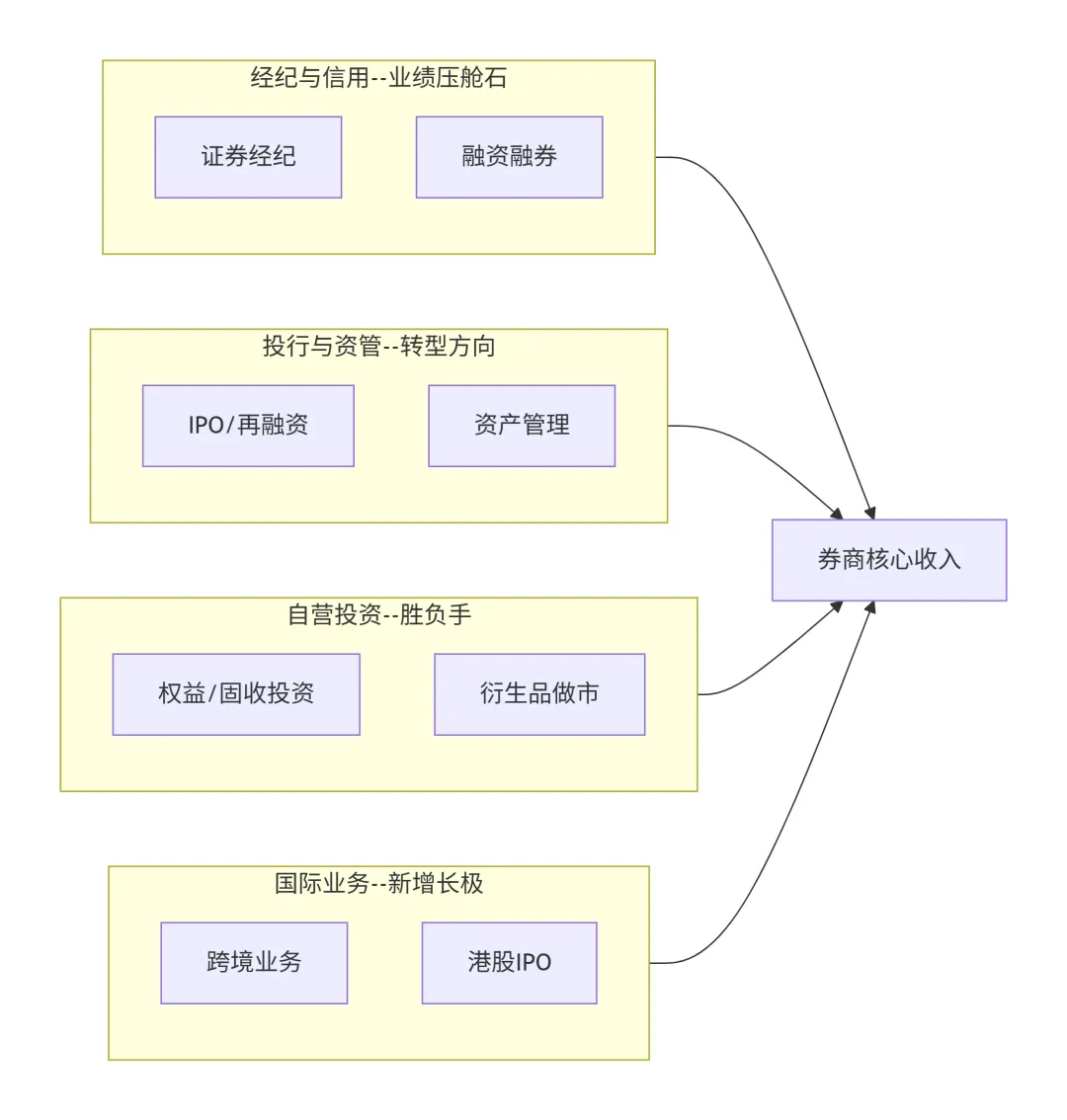
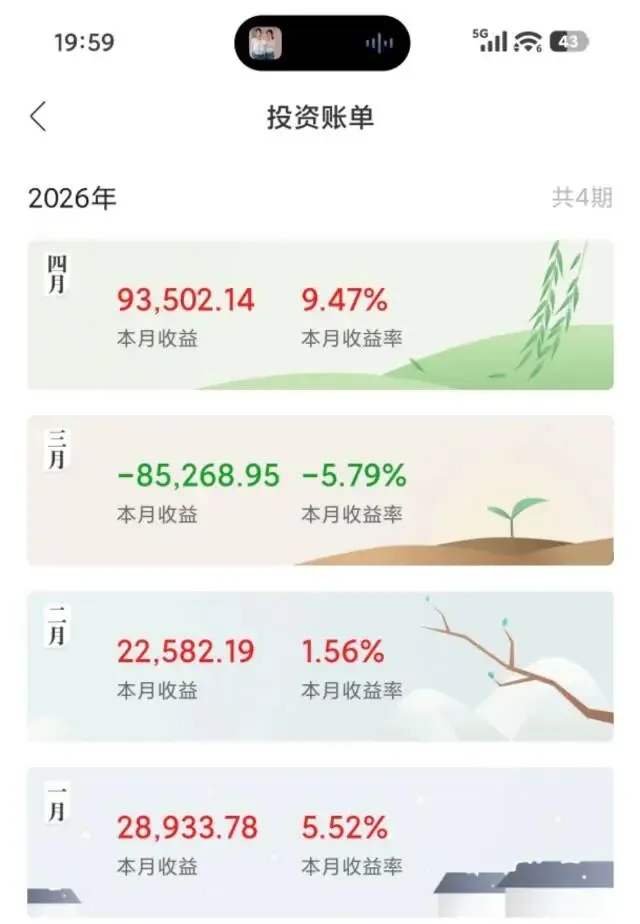
 研报速递
研报速递 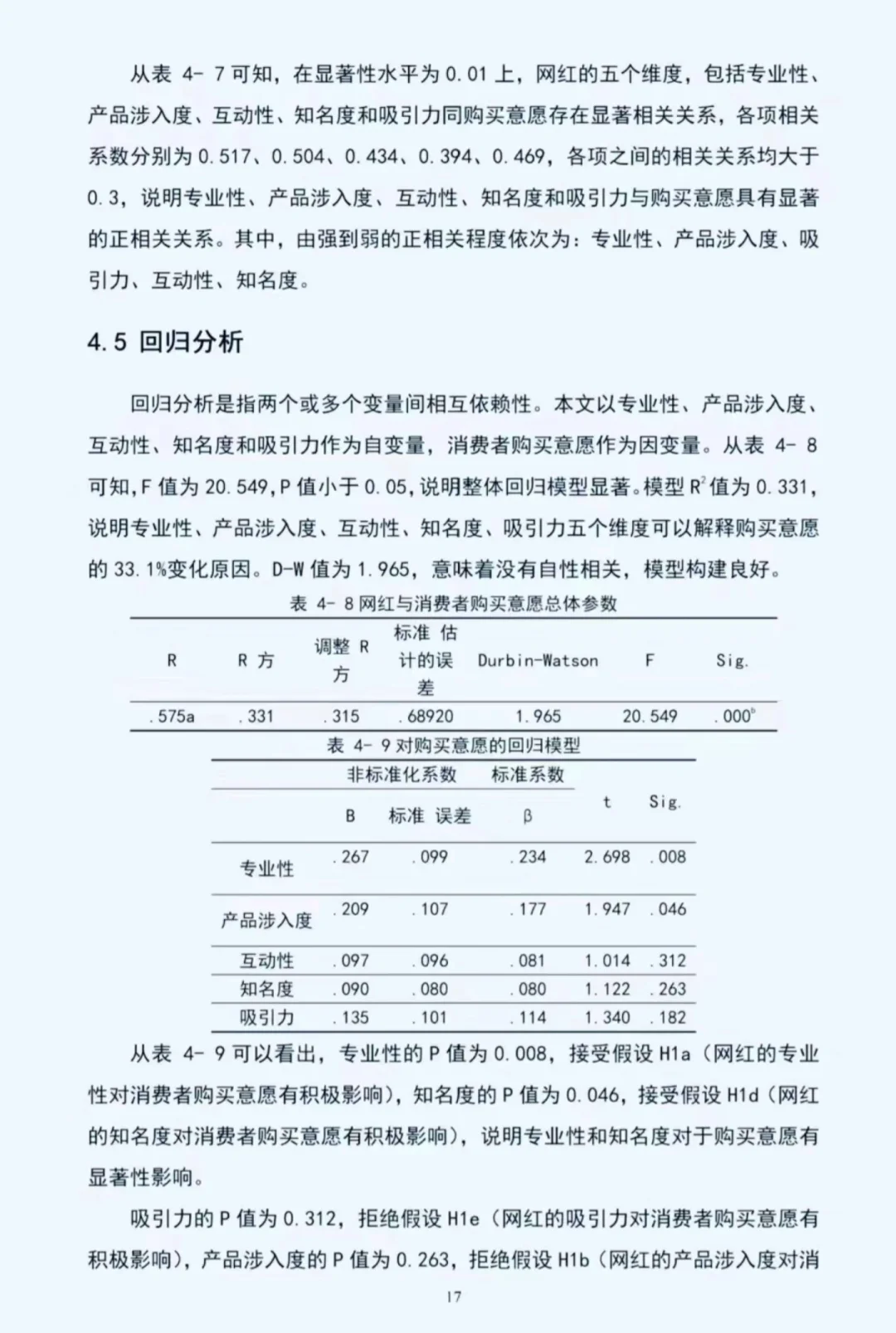
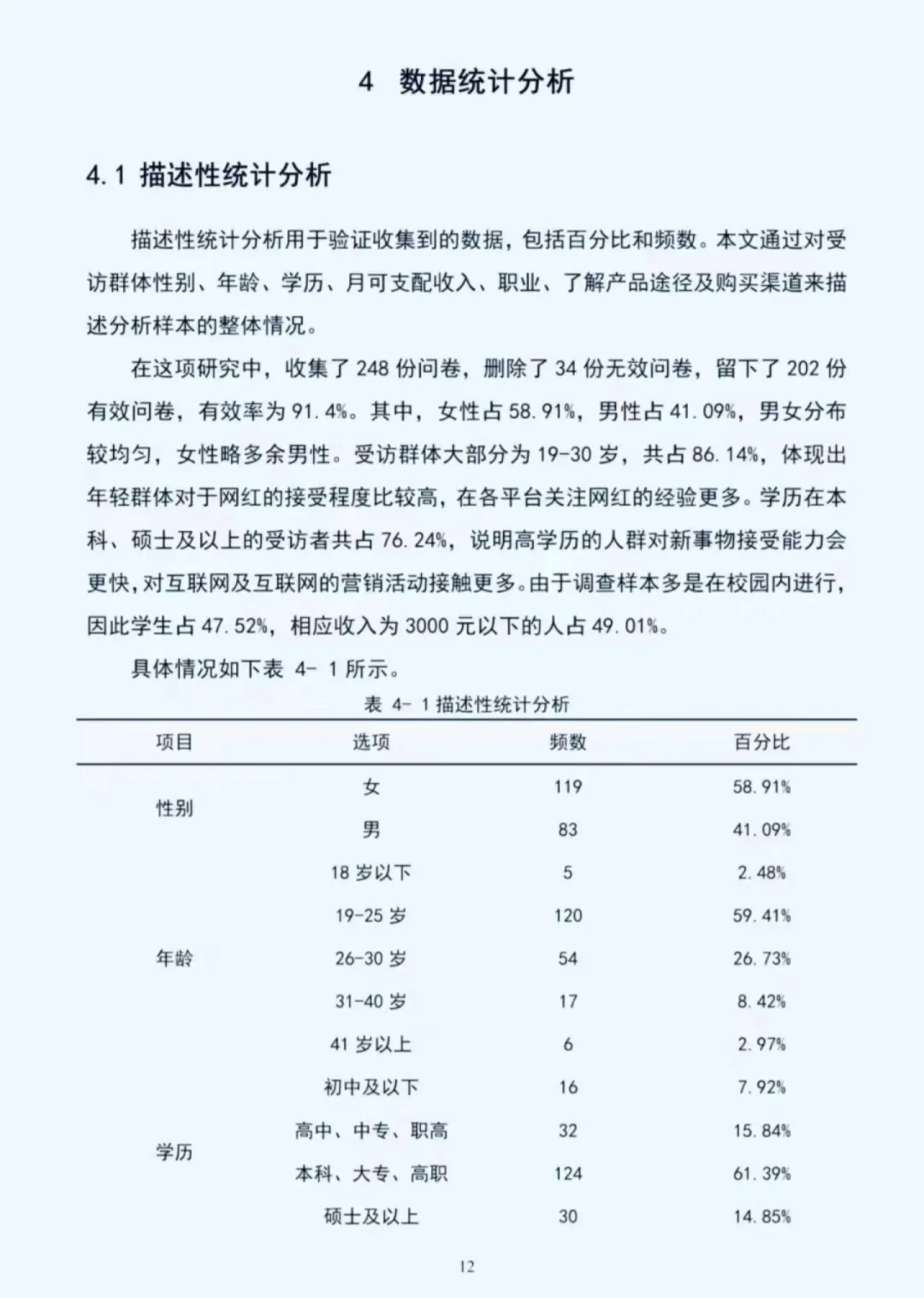
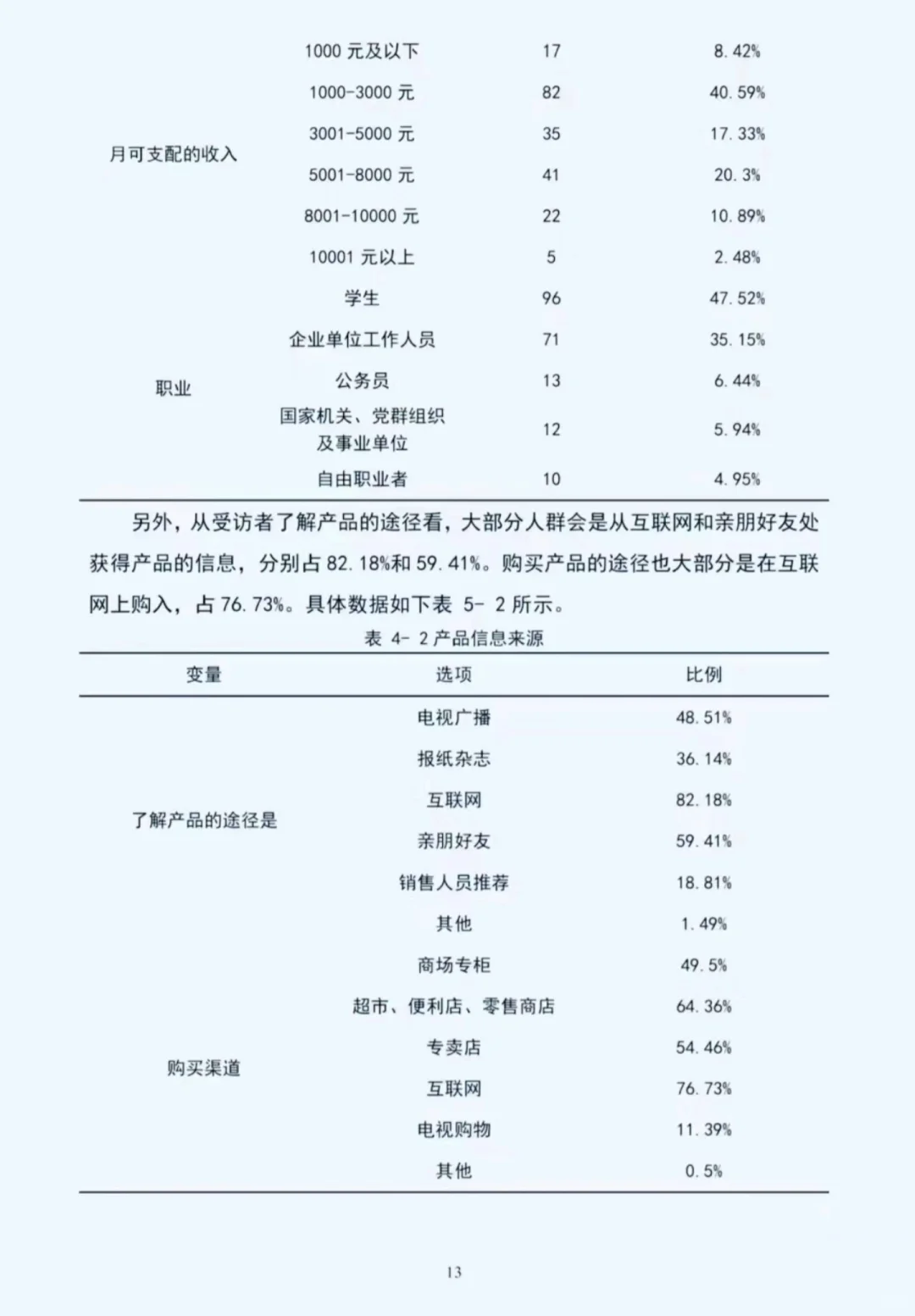

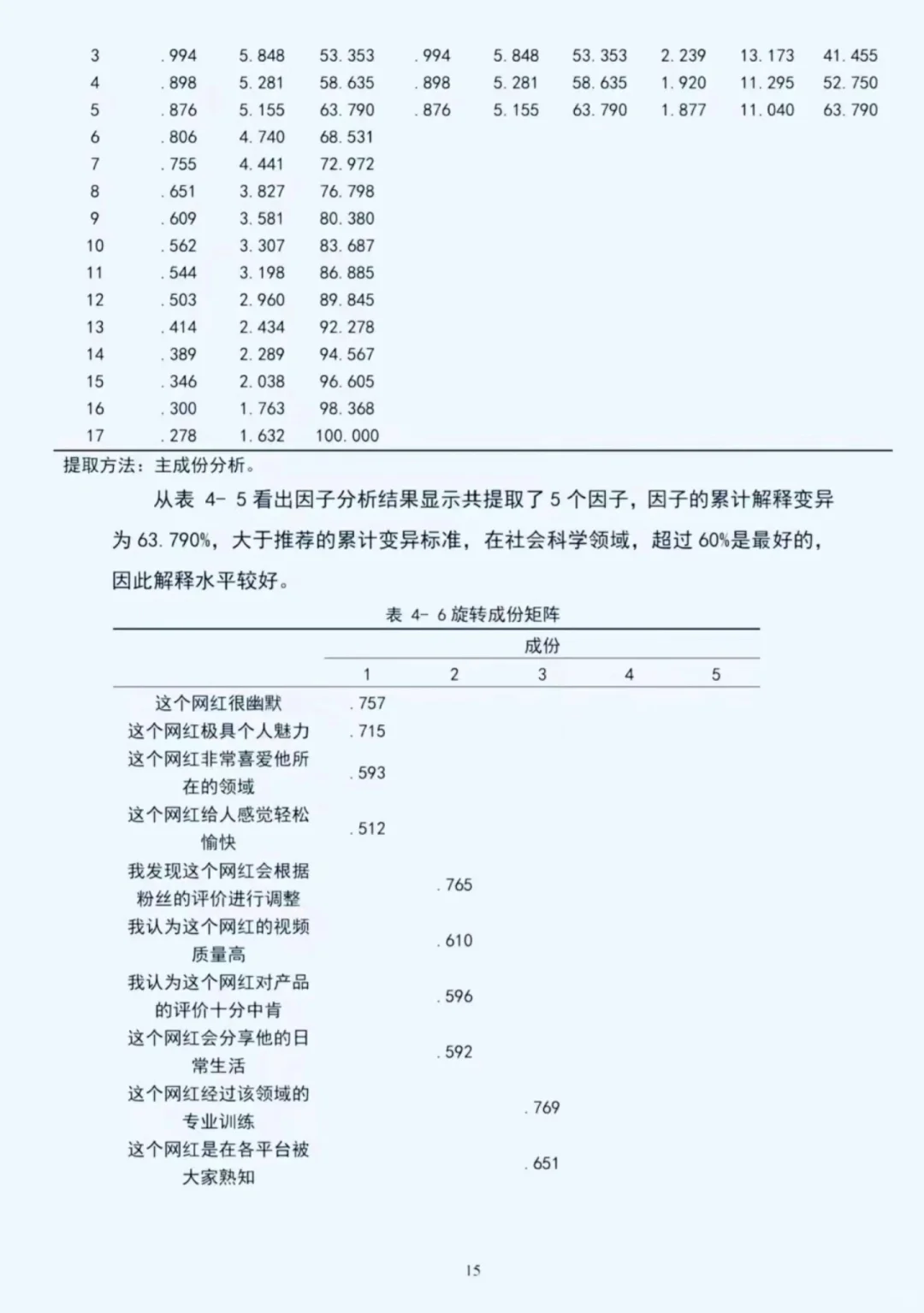

描述性统计\n提供研究变量的基本特征,让读者对数据有初步了解。\n对于连续变量,可以报告均值、标准差、最小值、最大值、中位数等。例如:“变量 X 的均值为 XX,标准差为 XX,最小值为 XX,最大值为 XX,中位数为 XX。”\n对于分类变量,报告各类别的频数和百分比。例如:“变量 Y 有三个类别,类别 A 有 XX 个样本,占比 XX%;类别 B 有 XX 个样本,占比 XX%;类别 C 有 XX 个样本,占比 XX%。”\n信效度分析\n信度分析\n检验测量工具的稳定性和一致性。\n常用 Cronbach\'s α 系数来衡量内部一致性信度。例如:“本研究采用 Cronbach\'s α 系数来检验量表的信度。结果显示,量表的 Cronbach\'s α 系数为 XX,表明该量表具有较高的内部一致性信度。”\n若使用重测信度,可以报告两次测量结果的相关系数。\n效度分析\n检验测量工具是否能够准确测量研究变量。\n内容效度:通过专家评估等方法说明测量工具的内容是否涵盖了研究变量的各个方面。\n结构效度:常用因子分析等方法检验。例如:“对量表进行因子分析,结果提取出 XX 个因子,累计方差贡献率为 XX%,表明该量表具有较好的结构效度。”\n效标效度:将测量工具与一个已知有效的标准进行比较,报告相关系数。\n相关分析\n探讨研究变量之间的线性关系。\n计算相关系数,常用 Pearson 相关系数或 Spearman 相关系数。\n解释相关系数的大小和方向。例如:“变量 X 与变量 Y 的相关系数为 XX,呈正相关/负相关关系。这表明变量 X 与变量 Y 之间存在一定的线性关系。”\n回归分析\n确定自变量对因变量的影响程度。\n建立回归模型,明确自变量和因变量。例如:“以变量 Y 为因变量,变量 X1、X2、X3 为自变量,建立多元线性回归模型。”\n报告回归系数、标准误、t 值、p 值等。例如:“变量 X1 的回归系数为 XX,标准误为 XX,t 值为 XX,p 值为 XX。”\n解释回归系数的意义。例如:“变量 X1 的回归系数为正,表明变量 X1 对因变量 Y 有正向影响。”\n评估回归模型的拟合优度,可报告 R² 值等。例如:“回归模型的 R² 为 XX,表明该模型能够解释因变量 Y 的 XX%的变异。”\n#spss统计分析 #实证分析 #spss #spss数据分析代做 #spss数据分析 #spss教程




发表评论
发表评论: